 Kubernetes - 深入 Pod
Kubernetes - 深入 Pod
# Pod 配置文件
创建一个 Pod,我们可以通过 yaml 文件来创建,如我们创建了一个文件:nginx-demo.yml
apiVersion: v1 # api 文档版本
kind: Pod # 资源对象类型,也可以配置为像 Deployment、StatefulSet 这一类的对象
metadata: # Pod 相关的元数据,用于描述 Pod 的数据
name: nginx-demo # Pod 的名称
labels: # 定义 Pod 的标签
type: app # 自定义 label 标签,名字为 type,值为 app
test: 1.0.0 # 自定义 label 标签,描述 Pod 版本号
namespace: 'default' # 命名空间的配置
spec: # 期望 Pod 按照这里面的描述进行创建
containers: # 对于 Pod 中的容器描述
- name: nginx # 容器的名称
image: nginx:1.7.9 # 指定容器的镜像
imagePullPolicy: IfNotPresent # 镜像拉取策略,指定如果本地有就用本地的,如果没有就拉取远程的
startupProbe:
httpGet:
path: /api/startup
port: 80
livenessProbe:
failureThreshold: 5
httpGet:
path: /health
port: 8080
scheme: HTTP
readinessProbe:
failureThreshold: 3 # 错误次数
httpGet:
path: /ready
port: 8181
scheme: HTTP
periodSeconds: 10 # 间隔时间
successThreshold: 1
timeoutSeconds: 1
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
command: # 指定容器启动时执行的命令
- nginx
- -g
- 'daemon off;' # nginx -g 'daemon off;'
workingDir: /usr/share/nginx/html # 定义容器启动后的工作目录
ports:
- name: http # 端口名称
containerPort: 80 # 描述容器内要暴露什么端口
protocol: TCP # 描述该端口是基于哪种协议通信的
- env: # 环境变量
name: JVM_OPTS # 环境变量名称
value: '-Xms128m -Xmx128m' # 环境变量的值
reousrces:
requests: # 最少需要多少资源
cpu: 100m # 限制 cpu 最少使用 0.1 个核心
memory: 128Mi # 限制内存最少使用 128兆
limits: # 最多可以用多少资源
cpu: 200m # 限制 cpu 最多使用 0.2 个核心
memory: 256Mi # 限制 最多使用 256兆
restartPolicy: OnFailure # 重启策略,只有失败的情况才会重启
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
然后执行命令:
kubectl create -f nginx-demo.yml
然后就创建了一个 pod
kubectl get po
# 探针
容器内应用的监测机制,根据不同的探针来判断容器应用当前的状态。
# 类型
# StartupProbe
k8s 1.16 版本新增的探针,用于判断应用程序是否已经启动了。
当配置了 startupProbe 后,会先禁用其他探针,直到 startupProbe 成功后,其他探针才会继续。
作用:由于有时候不能准确预估应用一定是多长时间启动成功,因此配置另外两种方式不方便配置初始化时长来检测,而配置了 statupProbe 后,只有在应用启动成功了,才会执行另外两种探针,可以更加方便的结合使用另外两种探针使用。
可在 yaml 文件的 spec.containers 下配置:
startupProbe:
httpGet:
path: /api/startup
port: 80
2
3
4
# LivenessProbe
用于探测容器中的应用是否运行,如果探测失败,kubelet 会根据配置的重启策略进行重启,若没有配置,默认就认为容器启动成功,不会执行重启策略。
可在 yaml 文件的 spec.containers 下配置:
livenessProbe:
failureThreshold: 5
httpGet:
path: /health
port: 8080
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
2
3
4
5
6
7
8
9
10
# ReadinessProbe
用于探测容器内的程序是否健康,它的返回值如果返回 success,那么就认为该容器已经完全启动,并且该容器是可以接收外部流量的。
readinessProbe:
failureThreshold: 3 # 错误次数
httpGet:
path: /ready
port: 8181
scheme: HTTP
periodSeconds: 10 # 间隔时间
successThreshold: 1
timeoutSeconds: 1
2
3
4
5
6
7
8
9
这三种探针的配置信息基本一样,只是名字不一样
# 探测方式
上面介绍的三个探针的 yaml 配置就用到了探测方式:
# ExecAction
在容器内部执行一个命令,如果返回值为 0,则任务容器时健康的。
如
livenessProbe:
exec:
command:
- cat
- /health
2
3
4
5
# TCPSocketAction
通过 tcp 连接监测容器内端口是否开放,如果开放则证明该容器健康。
livenessProbe:
tcpSocket:
port: 80
2
3
# HTTPGetAction
生产环境用的较多的方式,发送 HTTP 请求到容器内的应用程序,如果接口返回的状态码在 200~400 之间,则认为容器健康。
livenessProbe:
failureThreshold: 5
httpGet:
path: /health
port: 8080
scheme: HTTP
httpHeaders:
- name: xxx
value: xxx
2
3
4
5
6
7
8
9
# 参数配置
下面的配置可以作用在任意一个探针上,具体看上面的 Pod 配置文件。
initialDelaySeconds: 60 # 初始化时间
timeoutSeconds: 2 # 超时时间
periodSeconds: 5 # 监测间隔时间
successThreshold: 1 # 检查 1 次成功就表示成功
failureThreshold: 2 # 监测失败 2 次就表示失败
2
3
4
5
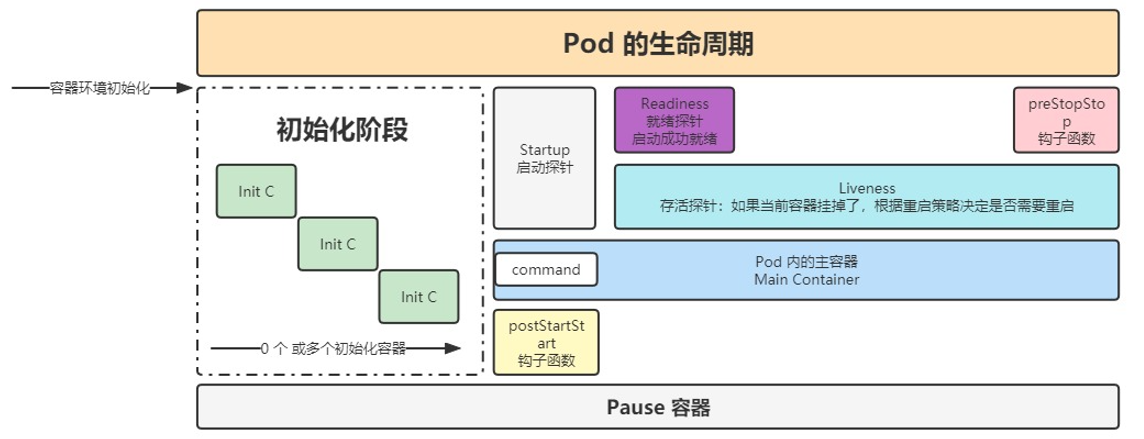
# 生命周期
Pod 完整的运行分为如图阶段:
容器环境初始化的初始化阶段,这个阶段会初始化容器需要的信息,我们可以在这个阶段做一些自己的动作,当初始化阶段结束后,则开始真正运行起来。
在容器刚运行成功后,会执行 postStart 钩子函数,这里我们做一些操作,类似于 Vue3 的 OnMounted,但是这个钩子不一定是容器启动后第一个执行的钩子, 因为如图的 command 命令也在这执行,command 命令可能在 postStart 前执行,可能两个一起执行,也可能在 postStart 后执行,所以不稳定。
在容器运行的过程,就会有上面介绍的三个探针进行监控。
当容器销毁前,会执行 preStop 钩子函数,我们可以在 preStop 做一些「善后工作」,如下介绍。
lifecycle:
postStart: # 容创建完成后执行的动作,不能保证该操作一定在容器的 command 之前执行,一般不使用
exec: # 可以是 exec / httpGet / tcpSocket
command:
- sh
- -c
- 'mkdir /data'
preStop: # 在容器停止前执行的动作
httpGet: # 发送一个 http 请求
path: /
port: 80
exec: # 执行一个命令
command:
- sh
- -c
- sleep 9
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
钩子函数里的使用和探测方式一样。
# Pod 退出流程
当 Pod 被删除时:
Endpoint 先删除 pod 的 ip 地址
然后 Pod 变成 Terminating 状态:Terminating 状态会给 Pod 一个宽限期,让 Pod 去执行一些清理或销毁操作
设置宽限期配置参数(默认 30 秒):
# 作用与 pod 中的所有容器 terminationGracePeriodSeconds: 40 # 30 秒才真正销毁 Pod containers: - xxx1
2
3
4最后执行 preStop 的指令
# PreStop 的应用
如果应用销毁操作耗时需要比较长,可以在 preStop 按照如下方式进行配置:
preStop:
exec:
command:
- sh
- -c
- 'sleep 20; kill pgrep java'
2
3
4
5
6
但是需要注意,由于 k8s 默认给 pod 的停止宽限时间为 30s,如果我们停止操作会超过 30s 时,不要光设置 sleep 50,还要将 terminationGracePeriodSeconds: 30 也更新成更长的时间,否则 k8s 最多只会在这个时间的基础上再宽限几秒,不会真正等待 50s
应用有:注册中心下线、数据清理、数据销毁。
# Terminating 强制删除
一键强制删除 k8s 集群中所有 Terminating 状态的 pod
kubectl get po --all-namespaces|grep Terminating| awk '{print $1"\t"$2}'| xargs -l bash -c 'kubectl delete po $1 -n $0 --force --grace-period=0'