 Reactor - 高级特性与概念
Reactor - 高级特性与概念
# 打包重用操作符
从代码整洁的角度来说,重用代码是一个好办法。Reactor 提供了几种帮你打包重用代码的方式, 主要通过使用操作符或者常用的「操作符组合」的方法来实现。如果你觉得一段操作链很常用, 你可以将这段操作链打包封装后备用。
# 使用 transform 操作符
transform 操作符可以将一段操作链封装为一个函数式(function)。这个函数式能在操作期(assembly time) 将被封装的操作链中的操作符还原并接入到调用 transform 的位置。这样做和直接将被封装的操作符 加入到链上的效果是一样的。示例如下:
Function<Flux<String>, Flux<String>> filterAndMap =
f -> f.filter(color -> !color.equals("orange"))
.map(String::toUpperCase);
Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple"))
.doOnNext(System.out::println)
.transform(filterAndMap)
.subscribe(d -> System.out.println("Subscriber to Transformed MapAndFilter: "+d));
2
3
4
5
6
7
8
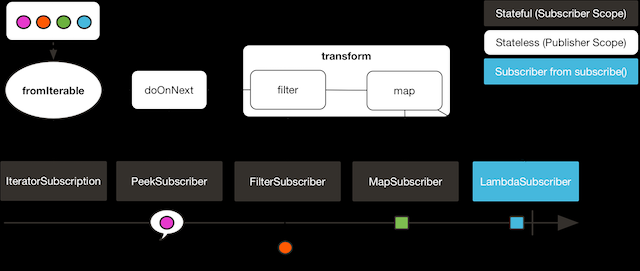
上边例子的输出如下:
blue
Subscriber to Transformed MapAndFilter: BLUE
green
Subscriber to Transformed MapAndFilter: GREEN
orange
purple
Subscriber to Transformed MapAndFilter: PURPLE
2
3
4
5
6
7
# 使用 compose 操作符
compose 操作符与 transform 类似,也能够将几个操作符封装到一个函数式中。 主要的区别就是,这个函数式作用到原始序列上的话,是 基于每一个订阅者的(on a per-subscriber basis) 。这意味着它对每一个 subscription 可以生成不同的操作链(通过维护一些状态值)。 如下例所示:
AtomicInteger ai = new AtomicInteger();
Function<Flux<String>, Flux<String>> filterAndMap = f -> {
if (ai.incrementAndGet() == 1) {
return f.filter(color -> !color.equals("orange"))
.map(String::toUpperCase);
}
return f.filter(color -> !color.equals("purple"))
.map(String::toUpperCase);
};
Flux<String> composedFlux =
Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple"))
.doOnNext(System.out::println)
.compose(filterAndMap);
composedFlux.subscribe(d -> System.out.println("Subscriber 1 to Composed MapAndFilter :"+d));
composedFlux.subscribe(d -> System.out.println("Subscriber 2 to Composed MapAndFilter: "+d));
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
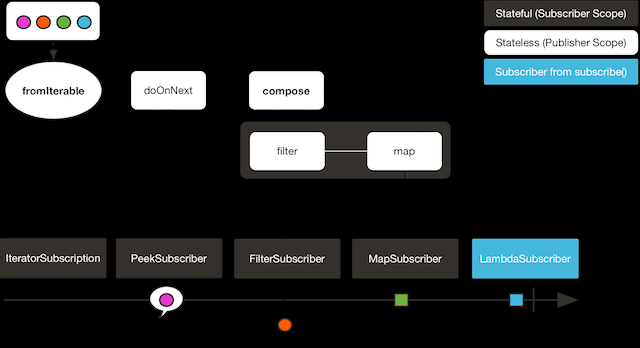
上边的例子输出如下:
blue
Subscriber 1 to Composed MapAndFilter :BLUE
green
Subscriber 1 to Composed MapAndFilter :GREEN
orange
purple
Subscriber 1 to Composed MapAndFilter :PURPLE
blue
Subscriber 2 to Composed MapAndFilter: BLUE
green
Subscriber 2 to Composed MapAndFilter: GREEN
orange
Subscriber 2 to Composed MapAndFilter: ORANGE
purple
2
3
4
5
6
7
8
9
10
11
12
13
14
# Hot vs Cold
到目前为止,我们一直认为 Flux(和 Mono)都是这样的:它们都代表了一种异步的数据序列, 在订阅(subscribe)之前什么都不会发生。
但是实际上,广义上有两种发布者:「热」与「冷」(hot and cold)。
(本文档)到目前介绍的其实都是 cold 家族的发布者。它们为每一个订阅(subscription) 都生成数据。如果没有创建任何订阅(subscription),那么就不会生成数据。
试想一个 HTTP 请求:每一个新的订阅者都会触发一个 HTTP 调用,但是如果没有订阅者关心结果的话, 那就不会有任何调用。
另一方面,热 发布者,不依赖于订阅者的数量。即使没有订阅者它们也会发出数据, 如果有一个订阅者接入进来,那么它就会收到订阅之后发出的元素。对于热发布者, 在你订阅它之前,确实已经发生了什么。
just 是 Reactor 中少数几个「热」操作符的例子之一:它直接在组装期(assembly time) 就拿到数据,如果之后有谁订阅它,就重新发送数据给订阅者。再拿 HTTP 调用举例,如果给 just 传入的数据是一个 HTTP 调用的结果,那么之后在初始化 just 的时候才会进行唯一的一次网络调用。
如果想将 just 转化为一种 冷 的发布者,你可以使用 defer。它能够将刚才例子中对 HTTP 的请求延迟到订阅时(这样的话,对于每一个新的订阅来说,都会发生一次网络调用)。
Reactor 中多数其他的 热 发布者是扩展自
Processor的。
考虑其他两个例子,如下是第一个例子:
Flux<String> source = Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple"))
.doOnNext(System.out::println)
.filter(s -> s.startsWith("o"))
.map(String::toUpperCase);
source.subscribe(d -> System.out.println("Subscriber 1: "+d));
source.subscribe(d -> System.out.println("Subscriber 2: "+d));
2
3
4
5
6
7
第一个例子输出如下:
blue
green
orange
Subscriber 1: ORANGE
purple
blue
green
orange
Subscriber 2: ORANGE
purple
2
3
4
5
6
7
8
9
10
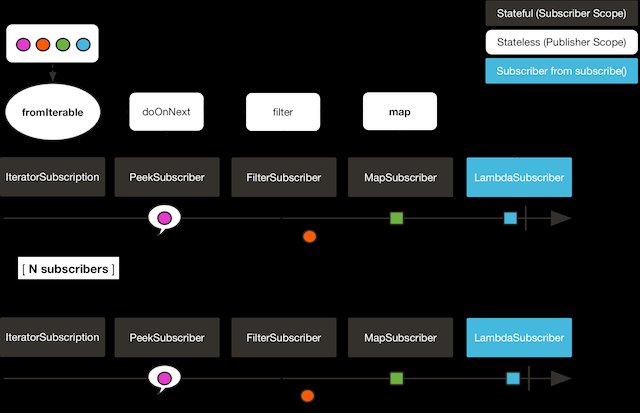
两个订阅者都触发了所有的颜色,因为每一个订阅者都会让构造 Flux 的操作符运行一次。
将下边的例子与第一个例子对比:
UnicastProcessor<String> hotSource = UnicastProcessor.create();
Flux<String> hotFlux = hotSource.publish()
.autoConnect()
.map(String::toUpperCase);
hotFlux.subscribe(d -> System.out.println("Subscriber 1 to Hot Source: "+d));
hotSource.onNext("blue");
hotSource.onNext("green");
hotFlux.subscribe(d -> System.out.println("Subscriber 2 to Hot Source: "+d));
hotSource.onNext("orange");
hotSource.onNext("purple");
hotSource.onComplete();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
第二个例子输出如下:
Subscriber 1 to Hot Source: BLUE
Subscriber 1 to Hot Source: GREEN
Subscriber 1 to Hot Source: ORANGE
Subscriber 2 to Hot Source: ORANGE
Subscriber 1 to Hot Source: PURPLE
Subscriber 2 to Hot Source: PURPLE
2
3
4
5
6
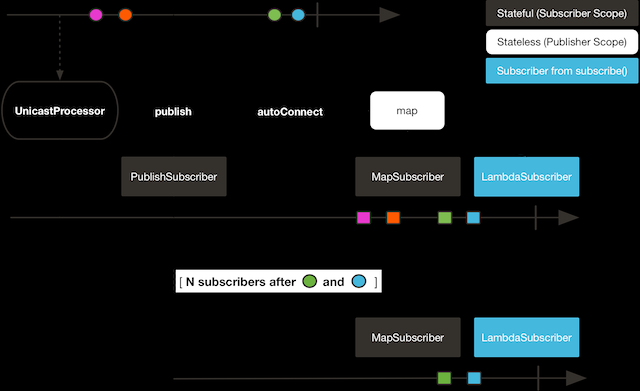
第一个订阅者收到了所有的四个颜色,第二个订阅者由于是在前两个颜色发出之后订阅的, 故而收到了之后的两个颜色,在输出中有两次 "ORANGE" 和 "PURPLE"。从这个例子可见, 无论是否有订阅者接入进来,这个 Flux 都会运行。
# 使用 ConnectableFlux 对多个订阅者进行广播
有时候,你不仅想要延迟到某一个订阅者订阅之后才开始发出数据,可能还希望在多个订阅者 到齐 之后 才开始。
ConnectableFlux 的用意便在于此。Flux API 中有两种主要的返回 ConnectableFlux 的方式:publish 和 replay。
publish会尝试满足各个不同订阅者的需求(背压),并综合这些请求反馈给源。 尤其是如果有某个订阅者的需求为0,publish 会 暂停 它对源的请求。replay将对第一个订阅后产生的数据进行缓存,最多缓存数量取决于配置(时间/缓存大小)。 它会对后续接入的订阅者重新发送数据。
ConnectableFlux 提供了多种对下游订阅的管理。包括:
connect当有足够的订阅接入后,可以对 flux 手动执行一次。它会触发对上游源的订阅。autoConnect(n)与 connect 类似,不过是在有n个订阅的时候自动触发。refCount(n)不仅能够在订阅者接入的时候自动触发,还会检测订阅者的取消动作。如果订阅者数量不够, 会将源「断开连接」,再有新的订阅者接入的时候才会继续「连上」源。refCount(int, Duration)增加了一个 "优雅的倒计时":一旦订阅者数量太低了,它会等待Duration的时间,如果没有新的订阅者接入才会与源「断开连接」。
示例如下:
Flux<Integer> source = Flux.range(1, 3)
.doOnSubscribe(s -> System.out.println("subscribed to source"));
ConnectableFlux<Integer> co = source.publish();
co.subscribe(System.out::println, e -> {}, () -> {});
co.subscribe(System.out::println, e -> {}, () -> {});
System.out.println("done subscribing");
Thread.sleep(500);
System.out.println("will now connect");
co.connect();
2
3
4
5
6
7
8
9
10
11
12
13
The preceding code produces the following output:
done subscribing
will now connect
subscribed to source
1
1
2
2
3
3
2
3
4
5
6
7
8
9
使用 autoConnect:
Flux<Integer> source = Flux.range(1, 3)
.doOnSubscribe(s -> System.out.println("subscribed to source"));
Flux<Integer> autoCo = source.publish().autoConnect(2);
autoCo.subscribe(System.out::println, e -> {}, () -> {});
System.out.println("subscribed first");
Thread.sleep(500);
System.out.println("subscribing second");
autoCo.subscribe(System.out::println, e -> {}, () -> {});
2
3
4
5
6
7
8
9
10
以上代码输出如下:
subscribed first
subscribing second
subscribed to source
1
1
2
2
3
3
2
3
4
5
6
7
8
9
# 三种分批处理方式
当你有许多的元素,并且想将他们分批处理,Reactor 总体上有三种方案:分组(grouping)、 窗口(windowing)、缓存(buffering)。 这三种在概念上类似,因为它们都是将 Flux<T> 进行聚集。分组和分段操作都会创建一个 Flux<Flux<T>>,而缓存操作得到的是一个 Collection<T>(应该是一个 Flux<Collection<T>>)。
# 进行分组
用 Flux<GroupedFlux<T>> 进行分组。
分组能够根据 key 将源 Flux<T> 拆分为多个批次。
对应的操作符是 groupBy。
每一组用 GroupedFlux<T> 类型表示,使用它的 key() 方法可以得到该组的 key。
在组内,元素并不需要是连续的。当源发出一个新的元素,该元素会被分发到与之匹配的 key 所对应的组中(如果还没有该 key 对应的组,则创建一个)。
这意味着组:
- 是互相没有交集的(一个元素只属于一个组)
- 会包含原始序列中任意位置的元素
- 不会为空
StepVerifier.create(
Flux.just(1, 3, 5, 2, 4, 6, 11, 12, 13)
.groupBy(i -> i % 2 == 0 ? "even" : "odd")
.concatMap(g -> g.defaultIfEmpty(-1) // 如果组为空,显示为 -1
.map(String::valueOf) // 转换为字符串
.startWith(g.key())) // 以该组的 key 开头
)
.expectNext("odd", "1", "3", "5", "11", "13")
.expectNext("even", "2", "4", "6", "12")
.verifyComplete();
2
3
4
5
6
7
8
9
10
分组操作适用于分组个数不多的场景。而且所有的组都必须被消费,这样
groupBy才能持续从上游获取数据。有时候这两种要求在一起——比如元素数量超多, 但是并行的用来消费的flatMap又太少的时候——会导致程序卡死。
# 进行 window 操作
使用 Flux<Flux<T>> 进行 window 操作。
window 操作是 根据个数、时间等条件,或能够定义边界的发布者(boundary-defining Publisher), 把源 Flux<T> 拆分为 windows。
对应的操作符有 window、windowTimeout、windowUntil、windowWhile,以及 windowWhen。
与 groupBy 的主要区别在于,窗口操作能够保持序列顺序。并且同一时刻最多只能有两个 window 是开启的。
它们 可以 重叠。操作符参数有 maxSize 和 skip,maxSize 指定收集多少个元素就关闭 window,而 skip 指定收集多数个元素后就打开下一个 window。所以如果 maxSize > skip 的话, 一个新的 window 的开启会先于当前 window 的关闭, 从而二者会有重叠。
重叠的 window 示例如下:
StepVerifier.create(
Flux.range(1, 10)
.window(5, 3) //overlapping windows
.concatMap(g -> g.defaultIfEmpty(-1)) //将 windows 显示为 -1
)
.expectNext(1, 2, 3, 4, 5)
.expectNext(4, 5, 6, 7, 8)
.expectNext(7, 8, 9, 10)
.expectNext(10)
.verifyComplete();
2
3
4
5
6
7
8
9
10
如果将两个参数的配置反过来(
maxSize<skip),序列中的一些元素就会被丢弃掉, 而不属于任何 window。
对基于判断条件的 windowUntil 和 windowWhile,如果序列中的元素不匹配判断条件, 那么可能导致 空 windows,如下例所示:
StepVerifier.create(
Flux.just(1, 3, 5, 2, 4, 6, 11, 12, 13)
.windowWhile(i -> i % 2 == 0)
.concatMap(g -> g.defaultIfEmpty(-1))
)
.expectNext(-1, -1, -1) //分别被奇数 1 3 5 触发
.expectNext(2, 4, 6) // 被 11 触发
.expectNext(12) // 被 13 触发
.expectNext(-1) // 空的 completion window,如果 onComplete 前的元素能够匹配上的话就没有这个了
.verifyComplete();
2
3
4
5
6
7
8
9
10
# 进行缓存
使用 Flux<List<T>> 进行缓存。
缓存与窗口类似,不同在于:缓存操作之后会发出 buffers (类型为Collection<T>, 默认是 List<T>),而不是 windows (类型为 Flux<T>)。
缓存的操作符与窗口的操作符是对应的:buffer、bufferTimeout、bufferUntil、bufferWhile, 以及bufferWhen。
如果说对于窗口操作符来说,是开启一个窗口,那么对于缓存操作符来说,就是创建一个新的集合, 然后对其添加元素。而窗口操作符在关闭窗口的时候,缓存操作符则是发出一个集合。
缓存操作也会有丢弃元素或内容重叠的情况,如下:
StepVerifier.create(
Flux.range(1, 10)
.buffer(5, 3) // 缓存重叠
)
.expectNext(Arrays.asList(1, 2, 3, 4, 5))
.expectNext(Arrays.asList(4, 5, 6, 7, 8))
.expectNext(Arrays.asList(7, 8, 9, 10))
.expectNext(Collections.singletonList(10))
.verifyComplete();
2
3
4
5
6
7
8
9
不像窗口方法,bufferUntil 和 bufferWhile 不会发出空的 buffer,如下例所示:
StepVerifier.create(
Flux.just(1, 3, 5, 2, 4, 6, 11, 12, 13)
.bufferWhile(i -> i % 2 == 0)
)
.expectNext(Arrays.asList(2, 4, 6)) // 被 11 触发
.expectNext(Collections.singletonList(12)) // 被 13 触发
.verifyComplete();
2
3
4
5
6
7
# 使用 ParallelFlux 进行并行处理
如今多核架构已然普及,能够方便的进行并行处理是很重要的。Reactor 提供了一种特殊的类型 ParallelFlux 来实现并行,它能够将操作符调整为并行处理方式。
你可以对任何 Flux 使用 parallel() 操作符来得到一个 ParallelFlux. 不过这个操作符本身并不会进行并行处理,而是将负载划分到多个「轨道(rails)」上 (默认情况下,轨道个数与 CPU 核数相等)。
为了配置 ParallelFlux 如何并行地执行每一个轨道,你需要使用 runOn(Scheduler)。 注意,Schedulers.parallel() 是推荐的专门用于并行处理的调度器。
下边有两个用于比较的例子,第一个如下:
Flux.range(1, 10)
.parallel(2) // 1
.subscribe(i -> System.out.println(Thread.currentThread().getName() + " -> " + i));
2
3
- 我们给定一个轨道数字,而不是依赖于 CPU 核数
下边是第二个例子:
Flux.range(1, 10)
.parallel(2)
.runOn(Schedulers.parallel())
.subscribe(i -> System.out.println(Thread.currentThread().getName() + " -> " + i));
2
3
4
第一个例子输出如下:
main -> 1
main -> 2
main -> 3
main -> 4
main -> 5
main -> 6
main -> 7
main -> 8
main -> 9
main -> 10
2
3
4
5
6
7
8
9
10
第二个例子在两个线程中并行执行,输出如下:
parallel-1 -> 1
parallel-2 -> 2
parallel-1 -> 3
parallel-2 -> 4
parallel-1 -> 5
parallel-2 -> 6
parallel-1 -> 7
parallel-1 -> 9
parallel-2 -> 8
parallel-2 -> 10
2
3
4
5
6
7
8
9
10
如果在并行地处理之后,需要退回到一个「正常」的 Flux 而使后续的操作链按非并行模式执行, 你可以对 ParallelFlux 使用 sequential() 方法。
注意,当你在对 ParallelFlux 使用一个 Subscriber 而不是基于 lambda 进行订阅(subscribe()) 的时候,sequential() 会自动地被偷偷应用。
注意 subscribe(Subscriber<T>) 会合并所有的执行轨道,而 subscribe(Consumer<T>) 会在所有轨道上运行。 如果 subscribe() 方法中是一个 lambda,那么有几个轨道,lambda 就会被执行几次。
你还可以使用 groups() 作为 Flux<GroupedFlux<T>> 进入到各个轨道或组里边, 然后可以通过 composeGroup() 添加额外的操作符。
# 替换默认的 Schedulers
就像我们在 调度器(Schedulers) 这一节看到的那样, Reactor Core 内置许多 Scheduler 的具体实现。 你可以用形如 new* 的工厂方法来创建调度器,每一种调度器都有一个单例对象,你可以使用单例工厂方法 (比如 Schedulers.elastic() 而不是 Schedulers.newElastic())来获取它。
当你不明确指定调度器的时候,那些需要调度器的操作符会使用这些默认的单例调度器对象。例如, Flux#delayElements(Duration) 使用的是 Schedulers.parallel() 调度器对象。
然而有些情况下,你可能需要「一刀切」(就不用对每一个操作符都传入你自己的调度器作为参数了) 地调整这些默认调度器。 一个典型的例子就是,假设你需要对每一个被调度的任务统计执行时长, 就想把默认的调度器包装一下,然后添加计时功能。
那么可以使用 Schedulers.Factory 类来改变默认的调度器。默认情况下,一个 Factory 会使用一些「命名比较直白」 的方法来创建所有的标准 Scheduler。每一个方法你都可以用自己的实现方式来重写。
此外,Factory 还提供一个额外的自定义方法 decorateExecutorService。它会在创建每一个 reactor-core 调度器——内部有一个 ScheduledExecutorService(即使是比如用 Schedulers.newParallel() 方法创建的这种非默认的调度器)——的时候被调用。
你可以通过调整 ScheduledExecutorService 来改变调度器:(decorateExecutorService 方法)通过一个 Supplier 参数暴露出来,你可以直接绕过这个 supplier 返回你自己的调度器实例,或者用 (Schedulers.ScheduledExecutorService 的)get() 得到默认实例,然后包装它, 这取决于配置的调度器类型。
当你搞定了一个定制好的
Factory后,你必须使用Schedulers.setFactory(Factory)方法来安装它。
最后,对于调度器来说,有一个可自定义的 hook:onHandleError。这个 hook 会在提交到这个调度器的 Runnable 任务抛出异常的时候被调用(注意,如果还设置了一个 UncaughtExceptionHandler, 那么它和 hook 都会被调用)。
# 使用全局的 Hooks
Reactor 还有另外一类可配置的应用于多种场合的回调,它们都在 Hooks 类中定义,总体来说有三类:
- 丢弃事件的 Hooks
- 内部错误 Hook
- 组装 Hooks
# 丢弃事件的 Hooks
当生成源的操作符不遵从响应式流规范的时候,Dropping hooks(用于处理丢弃事件的 hooks)会被调用。 这种类型的错误是处于正常的执行路径之外的(也就是说它们不能通过 onError 传播)。
典型的例子是,假设一个发布者即使在被调用 onCompleted 之后仍然可以通过操作符调用 onNext。 这种情况下,onNext 的值会被 丢弃,如果有多余的 onError 的信号亦是如此。
相应的 hook,onNextDropped 以及 onErrorDropped,可以提供一个全局的 Consumer, 以便能够在丢弃的情况发生时进行处理。例如,你可以使用它来对丢弃事件记录日志,或进行资源清理 (使用资源的值可能压根没有到达响应式链的下游)。
连续设置两次 hook 的话都会起作用:提供的每一个 consumer 都会被调用。使用 Hooks.resetOn*Dropped() 方法可以将 hooks 全部重置为默认。
# 内部错误 Hook
如果操作符在执行其 onNext、onError 以及 onComplete 方法的时候抛出异常,那么 onOperatorError 这一个 hook 会被调用。
与上一类 hook 不同,这个 hook 还是处在正常的执行路径中的。一个典型的例子就是包含一个 map 函数式的 map 操作符抛出的异常(比如零作为除数),这时候还是会执行到 onError 的。
首先,它会将异常传递给 onOperatorError。利用这个 hook 你可以检查这个错误(以及有问题的相关数据), 并可以 改变 这个异常。当然你还可以做些别的事情,比如记录日志或返回原始异常。
注意,onOperatorError hook 也可以被多次设置:你可以提供一个 String 为一个特别的 BiFunction 类型的函数式设置识别符,不同识别符的函数式都会被执行,当然,重复使用一个识别符的话, 则后来的设置会覆盖前边的设置。
因此,默认的 hook 可以使用 Hooks.resetOnOperatorError() 方法重置,而提供识别符的 hook 可以使用 Hooks.resetOnOperatorError(String) 方法来重置。
# 组装 Hooks
这些组装(assembly) hooks 关联了操作符的生命周期。它们会在一个操作链被组装起来的时候(即实例化的时候) 被调用。每一个新的操作符组装到操作链上的时候,onEachOperator 都会返回一个不同的发布者, 从而可以利用它动态调整操作符。onLastOperator 与之类似,不过只会在被操作链上的最后一个 (subscribe 调用之前的)操作符调用。
类似于 onOperatorError,也可以叠加,并且通过识别符来标识。也是用类似的方式重置全部或部分 hooks。
# 预置 Hooks
Hooks 工具类还提供了一些预置的 hooks。利用他们可以改变一些默认的处理方式,而不用自己 编写 hook:
onNextDroppedFail():onNextDropped通常会抛出Exceptions.failWithCancel()异常。 现在它默认还会以 DEBUG 级别对被丢弃的值记录日志。如果想回到原来的只是抛出异常的方式,使用onNextDroppedFail()。onOperatorDebug(): 这个方法会激活 开启调试模式。它与onOperatorErrorhook 关联,所以调用resetOnOperatorError()同时也会重置它。不过它内部也用到了特别的识别符, 你可以通过resetOnOperatorDebug()方法来重置它。
# 增加一个 Context 到响应式序列
当从命令式编程风格切换到响应式编程风格的时候,一个技术上最大的挑战就是线程处理。
与习惯做法不同的是,在响应式编程中,一个线程(Thread)可以被用于处理多个同时运行的异步序列 (实际上是非阻塞的)。执行过程也会经常从一个线程切换到另一个线程。
这样的情况下,对于开发者来说,如果依赖线程模型中相对「稳定」的特性——比如 ThreadLocal ——就会变得很难。因为它会让你将数据绑定到一个 线程 上,所以在响应式环境中使用就变得 比较困难。因此,将使用了 ThreadLocal 的库应用于 Reactor 的时候就会带来新的挑战。通常会更糟, 它用起来效果会更差,甚至会失败。 比如,使用 Logback 的 MDC 来存储日志关联的 ID,就是一个非常符合 这种情况的例子。
通常的对 ThreadLocal 的替代方案是将环境相关的数据 C,同业务数据 T 一起置于序列中, 比如使用 Tuple2<T, C>。这种方案看起来并不好,况且会在方法和 Flux 泛型中暴露环境数据信息。
自从版本 3.1.0,Reactor 引入了一个类似于 ThreadLocal 的高级功能:Context。它作用于一个 Flux 或一个 Mono 上,而不是应用于一个线程(Thread)。
为了说明,这里有个读写 Context 的简单例子:
String key = "message";
Mono<String> r = Mono.just("Hello")
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key)))
.subscriberContext(ctx -> ctx.put(key, "World"));
StepVerifier.create(r)
.expectNext("Hello World")
.verifyComplete();
2
3
4
5
6
7
8
9
接下来的几个小节,我们来了解 Context 是什么以及如何用,从而最终可以理解上边的例子。
这是一个主要面向库开发人员的高级功能。这需要开发者对
Subscription的生命周期 充分理解,并且明白它主要用于 subscription 相关的库。
# Context API
Context 是一个类似于 Map(这种数据结构)的接口:它存储键值(key-value)对,你需要通过 key 来获取值:
- key 和 value 都是
Object类型,所以Context可以包含任意数量的任意对象。 Context是 不可变的(immutable)。- 用
put(Object key, Object value)方法来存储一个键值对,返回一个新的Context对象。 你也可以用putAll(Context)方法将两个 context 合并为一个新的 context。 - 用
hasKey(Object key)方法检查一个 key 是否已经存在。 - 用
getOrDefault(Object key, T defaultValue)方法取回 key 对应的值(类型转换为T), 或在找不到这个 key 的情况下返回一个默认值。 - 用
getOrEmpty(Object key)来得到一个Optional<T>(context 会尝试将值转换为T)。 - 用
delete(Object key)来删除 key 关联的值,并返回一个新的Context。
创建一个
Context时,你可以用静态方法Context.of预先存储最多 5 个键值对。 它接受 2, 4, 6, 8 或 10 个Object对象,两两一对作为键值对添加到Context。 你也可以用Context.empty()方法来创建一个空的Context。
# 把 Context 绑定到 Flux and Writing
为了使用 context,它必须要绑定到一个指定的序列,并且链上的每个操作符都可以访问它。 注意,这里的操作符必须是 Reactor 内置的操作符,因为 Context 是 Reactor 特有的。
实际上,一个 Context 是绑定到每一个链中的 Subscriber 上的。 它使用 Subscription 的传播机制来让自己对每一个操作符都可见(从最后一个 subscribe 沿链向上)。
为了填充 Context ——只能在订阅时(subscription time)——你需要使用 subscriberContext 操作符。
subscriberContext(Context) 方法会将你提供的 Context 与来自下游(记住,Context 是从下游 向上游传播的)的 Context合并。 这通过调用 putAll 实现,最后会生成一个新的 Context 给上游。
你也可以用更高级的
subscriberContext(Function<Context, Context>)。它接受来自下游的Context,然后你可以根据需要添加或删除值,然后返回新的Context。你甚至可以返回一个完全不同 的对象,虽然不太建议这样(这样可能影响到依赖这个Context的库)。
# 读取 Context
填充 Context 是一方面,读取数据同样重要。多数时候,添加内容到 Context 是最终用户的责任, 但是利用这些信息是库的责任,因为库通常是客户代码的上游。
读取 context 数据使用静态方法 Mono.subscriberContext()。
# 简单的例子
本例的初衷是为了让你对如何使用 Context 有个更好的理解。
让我们先回头看一下最初的例子:
String key = "message";
Mono<String> r = Mono.just("Hello")
.flatMap( s -> Mono.subscriberContext() // 2
.map( ctx -> s + " " + ctx.get(key))) // 3
.subscriberContext(ctx -> ctx.put(key, "World")); // 1
StepVerifier.create(r)
.expectNext("Hello World") // 4
.verifyComplete();
2
3
4
5
6
7
8
9
- 操作链以调用
subscriberContext(Function)结尾,将"World"作为"message"这个 key 的 值添加到Context中 - 对源调用
flatMap用Mono.subscriberContext()方法拿到Context - 然后使用
map读取关联到"message"的值,然后与原来的值连接 - 最后
Mono<String>确实发出了"Hello World"
上边的数字顺序并不是按照代码行顺序排的,这并非错误:它代表了执行顺序。虽然
subscriberContext是链上的最后一个环节,但确实最先执行的(原因在于 subscription 信号 是从下游向上的)。
注意在你的操作链中,写入 与 读取 Context 的 相对位置 很重要:因为 Context 是不可变的,它的内容只能被上游的操作符看到,如下例所示:
String key = "message";
Mono<String> r = Mono.just("Hello")
.subscriberContext(ctx -> ctx.put(key, "World")) // 1
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.getOrDefault(key, "Stranger"))); // 2
StepVerifier.create(r)
.expectNext("Hello Stranger") // 3
.verifyComplete();
2
3
4
5
6
7
8
9
- 写入
Context的位置太靠上了 - 所以在
flatMap就没有 key 关联的值,使用了默认值 - 结果
Mono<String>发出了"Hello Stranger"
下面的例子同样说明了 Context 的不可变性(Mono.subscriberContext() 总是返回由 subscriberContext 配置的 Context):
String key = "message";
Mono<String> r = Mono.subscriberContext() // 1
.map( ctx -> ctx.put(key, "Hello")) // 2
.flatMap( ctx -> Mono.subscriberContext()) // 3
.map( ctx -> ctx.getOrDefault(key,"Default")); // 4
StepVerifier.create(r)
.expectNext("Default") // 5
.verifyComplete();
2
3
4
5
6
7
8
9
10
- 拿到
Context - 在
map方法中我们尝试修改它 - 在
flatMap中再次获取Context - 读取
Context中可能的值 - 值从来没有被设置为
"Hello"
类似的,如果多次对 Context 中的同一个 key 赋值的话,要看 写入的相对顺序 : 读取 Context 的操作符只能拿到下游最近的一次写入的值,如下例所示:
String key = "message";
Mono<String> r = Mono.just("Hello")
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key)))
.subscriberContext(ctx -> ctx.put(key, "Reactor")) // 1
.subscriberContext(ctx -> ctx.put(key, "World")); // 2
StepVerifier.create(r)
.expectNext("Hello Reactor") // 3
.verifyComplete();
2
3
4
5
6
7
8
9
10
- 写入
"message"的值 - 另一次写入
"message"的值。 map方法值能拿到下游最近的一次写入的值:"Reactor"
这里,首先 Context 中的 key 被赋值 "World"。然后订阅信号(subscription signal)向上游 移动,又发生了另一次写入。这次生成了第二个不变的 Context,里边的值是 "Reactor"。之后, 数据开始流动, flatMap 拿到最近的 Context ,也就是第二个值为 Reactor 的 Context。
你可能会觉得 Context 是与数据信号一块传播的。如果是那样的话,在两次写入操作中间加入的一个 flatMap 会使用最上游的这个 Context。但并不是这样的,如下:
String key = "message";
Mono<String> r = Mono.just("Hello")
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key))) // 3
.subscriberContext(ctx -> ctx.put(key, "Reactor")) // 2
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key))) // 4
.subscriberContext(ctx -> ctx.put(key, "World")); // 1
StepVerifier.create(r)
.expectNext("Hello Reactor World") // 5
.verifyComplete();
2
3
4
5
6
7
8
9
10
11
12
- 这里是第一次赋值
- 这里是第二次赋值
- 第一个
flatMap看到的是第二次的赋值 - 第二个
flatMap将上一个的结果与 第一次赋值 的 context 值连接 Mono发出的是"Hello Reactor World"
原因在于 Context 是与 Subscriber 关联的,而每一个操作符访问的 Context 来自其下游的 Subscriber。
最后一个有意思的传播方式是,对 Context 的赋值也可以在一个 flatMap 内部,如下:
String key = "message";
Mono<String> r =
Mono.just("Hello")
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key))
)
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key))
.subscriberContext(ctx -> ctx.put(key, "Reactor")) // 1
)
.subscriberContext(ctx -> ctx.put(key, "World")); // 2
StepVerifier.create(r)
.expectNext("Hello World Reactor")
.verifyComplete();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 这个
subscriberContext不会影响所在flatMap之外的任何东西 - 这个
subscriberContext会影响主序列的Context
上边的例子中,最后发出的值是 "Hello World Reactor" 而不是 "Hello Reactor World",因为赋值 "Reactor" 的 subscriberContext 是作用于第二个 flatMap 的内部序列的。所以不会在主序列可见/ 传播,第一个 flatMap 也看不到它。传播(Propagation) + 不可变性(immutability)将类似 flatMap 这样的操作符中的创建的内部序列中的 Context 与外部隔离开来。
# 完整的例子
让我们来看一个实际的从 Context 中读取值的例子:一个响应式的 HTTP 客户端将一个 Mono<String> (用于 PUT 请求)作为数据源,同时通过一个特定的 key 使用 Context 将关联的ID信息放入请求头中。
从用户角度,是这样调用的:
doPut("www.example.com", Mono.just("Walter"))
为了传播一个关联ID,应该这样调用:
doPut("www.example.com", Mono.just("Walter"))
.subscriberContext(Context.of(HTTP_CORRELATION_ID, "2-j3r9afaf92j-afkaf"))
2
由上可见,用户代码使用了 subscriberContext 来为 Context 的 HTTP_CORRELATION_ID 赋值。上游的操作符是一个由 HTTP 客户端库返回的 Mono<Tuple2<Integer, String>> (一个简化的 HTTP 响应)。所以能够正确将信息从用户代码传递给库代码。
下边的例子演示了从库的角度由 context 读取值的模拟代码,如果能够找到关联ID,则「增加请求」:
static final String HTTP_CORRELATION_ID = "reactive.http.library.correlationId";
Mono<Tuple2<Integer, String>> doPut(String url, Mono<String> data) {
Mono<Tuple2<String, Optional<Object>>> dataAndContext =
data.zipWith(Mono.subscriberContext() // 1
.map(c -> c.getOrEmpty(HTTP_CORRELATION_ID))); // 2
return dataAndContext
.<String>handle((dac, sink) -> {
if (dac.getT2().isPresent()) { // 3
sink.next("PUT <" + dac.getT1() + "> sent to " + url + " with header X-Correlation-ID = " + dac.getT2().get());
}
else {
sink.next("PUT <" + dac.getT1() + "> sent to " + url);
}
sink.complete();
})
.map(msg -> Tuples.of(200, msg));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- 用
Mono.subscriberContext()拿到Context - 提取出关联ID的值——是一个
Optional - 如果值存在,那么就将其加入请求头
在这段库代码片段中,你可以看到它是如何将 Mono 和 Mono.subscriberContext() zip 起来的。 返回的是一个 Tuple2<String, Context>,这个 Context 包含来自下游的 HTTP_CORRELATION_ID 的值。
库代码接着用 map 读取出那个 key 的值 Optional<String>,如果值存在,将其作为 X-Correlation-ID 请求头。 最后一块而用 handle 来处理。
用来验证上边的库代码的测试程序如下:
@Test
public void contextForLibraryReactivePut() {
Mono<String> put = doPut("www.example.com", Mono.just("Walter"))
.subscriberContext(Context.of(HTTP_CORRELATION_ID, "2-j3r9afaf92j-afkaf"))
.filter(t -> t.getT1() < 300)
.map(Tuple2::getT2);
StepVerifier.create(put)
.expectNext("PUT <Walter> sent to www.example.com with header X-Correlation-ID = 2-j3r9afaf92j-afkaf")
.verifyComplete();
}
2
3
4
5
6
7
8
9
10
11
# 空值安全
虽然 Java 的类型系统没有表达空值安全(null-safety)的机制,但是 Reactor 现在提供了基于注解的用于声明 「可能为空(nullability)」的 API,类似于 Spring Framework 5 中提供的 API。
Reactor 自身就用到了这些注解,你也可以将其用于任何基于 Reactor 的自己的空值安全的 Java API 中。 不过,在 方法体内部 对「可能为空」的类型的使用就不在这一特性的范围内了。
这些注解是基于 JSR 305 (opens new window) 的注解(是受类似 IntelliJ IDEA 这样的工具支持的 JSR)作为元注解(meta-annotated)的。当 Java 开发者在编写空值安全的代码时, 它们能够提供有用的警告信息,以便避免在运行时(runtime)出现 NullPointerException 异常。 JSR 305 元注解使得工具提供商可以以一种通用的方式提供对空值安全的支持,从而 Reactor 的注解就不用重复造轮子了。
对于 Kotlin 1.1.5+,需要(同时也推荐)在项目 classpath 中添加对 JSR 305 的依赖。
它们也可在 Kotlin 中使用,Kotlin 原生支持 空值安全 (opens new window)。具体请参考 Null 值安全 。
reactor.util.annotation 包提供以下注解:
@NonNull(opens new window) 表明一个具体的参数、返回值或域值不能为null。(如果参数或返回值应用了@NonNullApi则无需再加它)@Nullable(opens new window) 表明一个参数、返回值或域值可以为null@NonNullApi(opens new window) 是一个包级别的注解,表明默认情况下参数或返回值不能为null
(Reactor 的空值安全的注解)对于通用类型参数(generic type arguments)、可变参数(varargs),以及数组元素(array elements) 尚不支持。参考 issue #878 (opens new window) 查看最新信息。