 RocketMQ - 介绍
RocketMQ - 介绍
# 引⾔
Message Queue(消息队列),从字⾯上理解:首先它是⼀个队列。FIFO 先进先出的数据结构——队列。消息队列就是所谓的存放消息的队列。
消息队列解决的不是存放消息的队列的目的,解决的是通信问题。
比如以电商订单系统为例,如果各服务之间使用同步通信,不仅耗时较久,且过程中受到网络波动的影响,不能保证高成功率。因此,使用异步的通信方式对架构进行改造。
使用异步的通信方式对模块间的调用进行解耦,可以快速的提升系统的吞吐量。上游执行完消息的发送业务后立即获得结果,下游多个服务订阅到消息后各自消费通过消息队列,屏蔽底层的通信协议,使得解藕和并行消费得以实现。
# RocketMQ 介绍
RocketMQ 是阿里巴巴 2016 年 MQ 中间件,使用 Java 语言开发,RocketMQ 是一款开源的 分布式消息系统,基于高可用分布式集群技术,提供低延时的、高可靠的消息发布与订阅服务。同时,广泛应用于多个领域,包括异步通信解耦、企业解决方案、金融支付、电信、电子商务、快递物流、广告营销、社交、即时通信、移动应用、手游、视频、物联网、车联网等。
具有以下特点:
- 能够保证严格的消息顺序
- 提供丰富的消息拉取模式
- 高效的订阅者水平扩展能力
- 实时的消息订阅机制
- 亿级消息堆积能力
随着使用中队列和虚拟主题的增加,阿里巴巴团队使用的 ActiveMQ IO 模块达到了瓶颈。为了尽力通过节流、断路器或降级来解决这个问题,但效果不佳。所以开始关注当时流行的消息传递解决方案 Kafka。不幸的是,Kafka 无法满足要求,尤其是在低延迟和高可靠性方面。在这种情况下,决定发明一种新的消息传递引警来处理更广泛的用例,从传统的发布/订阅场景到大容量实时零丢失交易系统。目前 RocketMO 已经开源给 Apache 基金会。如今,已有 100 多家公司在其业务中使用开源版本的 RocketMQ。
# 为什么要使用MQ
要做到系统解耦,当新的模块进来时,可以做到代码改动最小,能够解耦。
设置流程缓冲池,可以让后端系统按自身 吞吐 能力进行消费,不被冲垮,能够削峰,限流。
强弱依赖梳理能把非关键调用链路的操作异步化并提升整体系统的吞吐能力,能够异步。
MQ 的作用:削峰限流、异步、解耦合。
# 定义
中间件(缓存中间件 Redis Memcache 数据库中间件 Mycat Canal 消息中间件 MQ)
面向消息的 中间件(message-oriented middleware0) MOM 能够很好的解决以上的问题。
是指利用 高效可靠的消息传递机制进行与平台无关(跨平台)的数据交流,并基于数据通信来进行分布式系统的集成。
通过提供 消息传递和消息排队模型 在分布式环境下提供应用解耦,弹性伸缩,冗余存储,流量削峰,异步通信,数据同步等。
大致流程
发送者把消息发给消息服务器,消息服务器把消息存放在若干队列/主题中,在合适的时候,消息服务器会把消息转发给接受者。在这个过程中,发送和接受是异步的,也就是发送无需等待,发送者和接受者的生命周期也没有必然关系在发布 pub / 订阅 sub 模式下,也可以完成一对多的通信,可以让一个消息有多个接受者。
# 特点
# 异步处理模式
消息发送者可以发送一个消息而无需等待响应。消息发送者把消息发送到一条虚拟的通道(主题或队列)上。
消息接收者则订阅或监听该通道。一条信息可能最终转发给一个或多个消息接收者,这些接收者都无需对消息发送者做出回应。整个过程都是异步的。
案例:
也就是说,一个系统和另一个系统间进行通信的时候,假如系统 A 希望发送一个消息给系统 B,让它去处理,但是系统 A 不关注系统 B 到底怎么处理或者有没有处理好,所以系统 A 把消息发送给 MQ,然后就不管这条消息的「死活」了,接着系统 B 从 MQ 里面消费出来处理即可。至于怎么处理,是否处理完毕,什么时候处理,都是系统 B 的事,与系统 A 无关。
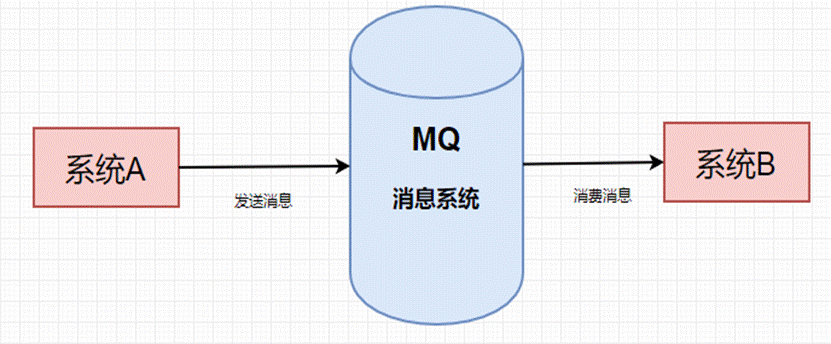
这样的一种通信方式,就是所谓的「异步」通信方式,对于系统 A 来说,只要把消息发给 MQ,然后系统 B 就会异步处去进行处理了,系统 A 不能「同步」的等待系统 B 处理完。这样的好处是什么呢?解耦。
# 应用系统的解耦
发送者和接收者不必了解对方,只需要确认消息。
发送者和接收者不必同时在线。
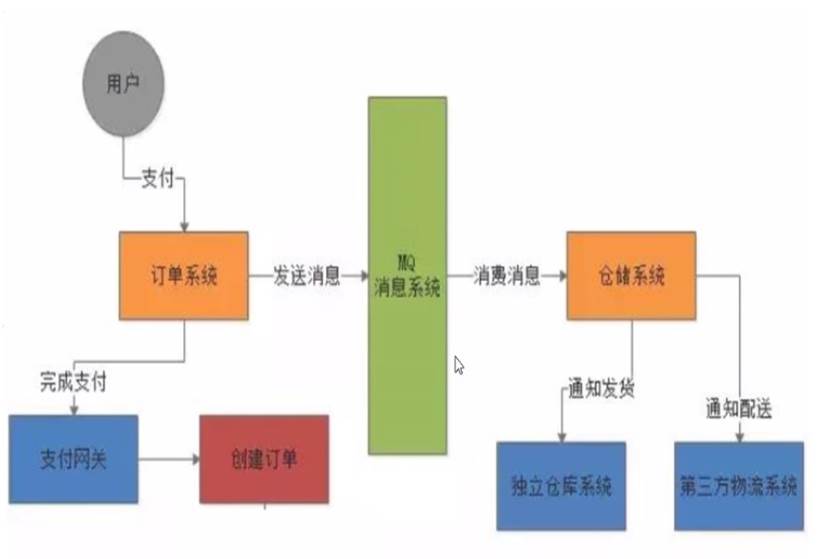
# 现实中的业务
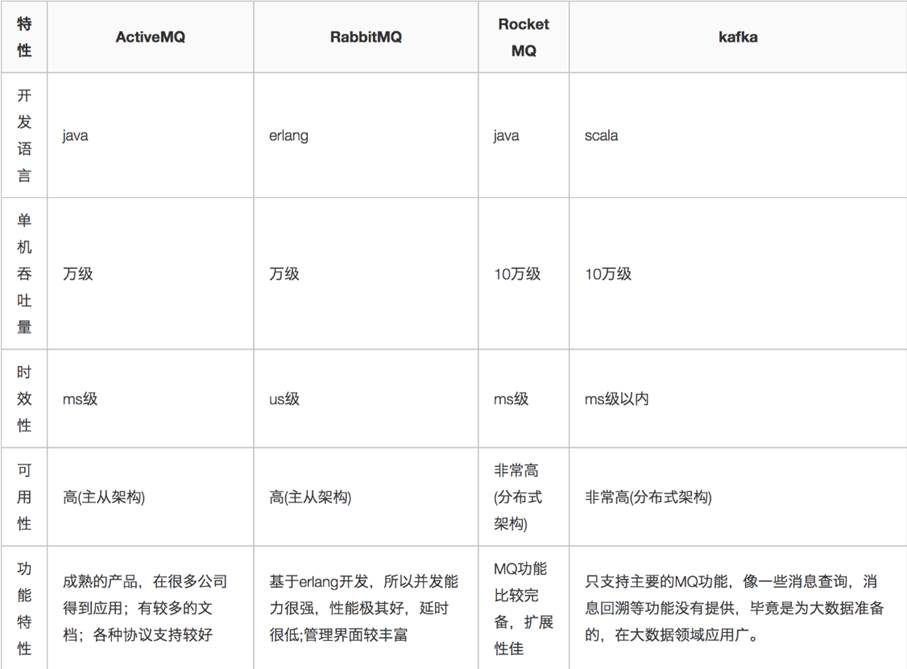
# 各个MQ产品的比较
# RocketMQ 的基本概念
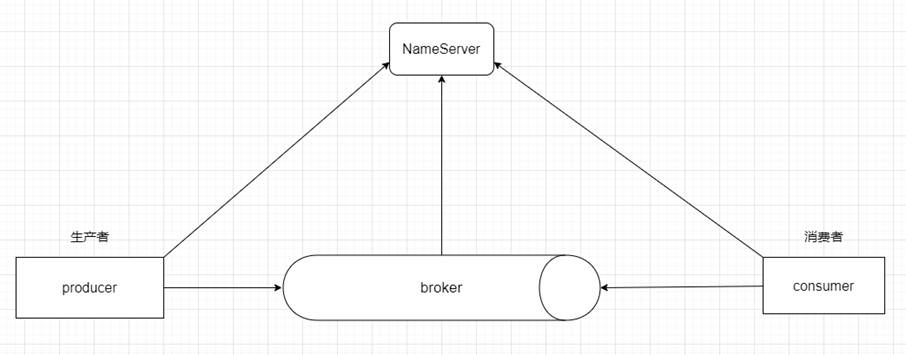
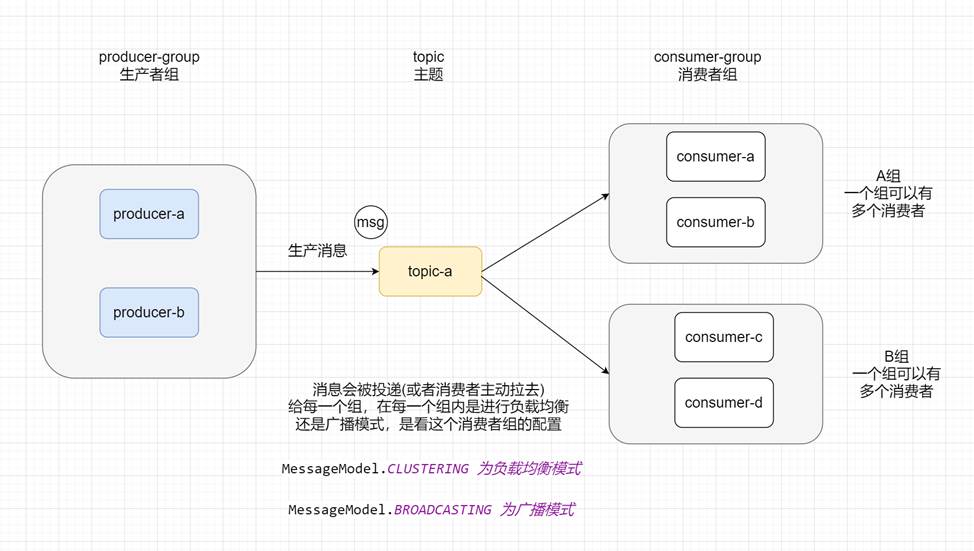
Producer:消息的发送者,生产者;举例:发件人
Consumer:消息接收者,消费者;举例:收件人
Broker:暂存和传输消息的通道;举例:快递
NameServer:管理 Broker;举例:各个快递公司的管理机构 相当于 Broker 的注册中心,保留了 Broker 的信息
Queue:队列,消息存放的位置,一个 Broker 中可以有多个队列
Topic:主题,消息的分类
ProducerGroup:生产者组
ConsumerGroup:消费者组,多个消费者组可以同时消费一个主题的消息
消息发送的流程是,Producer 询问 NameServer,NameServer 分配一个 Broker 然后 Consumer 也要询问 NameServer,得到一个具体的 Broker,然后消费消息。
# 生产和消费理解
# 技术架构
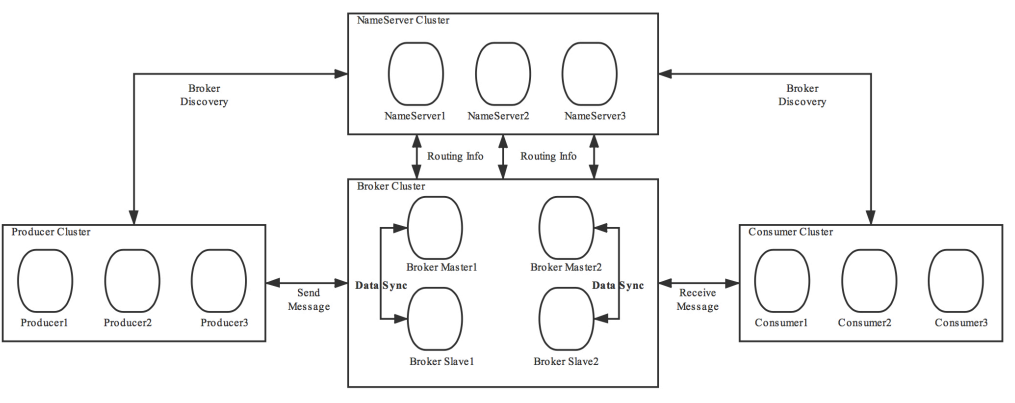
RocketMQ 架构上主要分为四部分,如上图所示:
- Producer: 消息发布的角色,支持分布式集群方式部署。Producer 通过 MQ 的负载均衡模块选择相应的 Broker 集群队列进行消息投递,投递的过程支持快速失败并且低延迟
- Consumer: 消息消费的角色,支持分布式集群方式部署。支持以 push 推,pull 拉两种模式对消息进行消费。同时也支持集群方式和广播方式的消费,它提供实时消息订阅机制,可以满足大多数用户的需求
- NameServer: NameServer 是一个非常简单的 Topic 路由注册中心,其角色类似 Dubbo 中的 zookeeper,支持 Broker 的动态注册与发现。主要包括两个功能:Broker 管理,NameServer 接受 Broker 集群的注册信息并且保存下来作为路由信息的基本数据。然后提供心跳检测机制,检查 Broker 是否还存活;路由信息管理,每个 NameServer 将保存关于 Broker 集群的整个路由信息和用于客户端查询的队列信息。然后 Producer 和 Conumser 通过 NameServer 就可以知道整个 Broker 集群的路由信息,从而进行消息的投递和消费。NameServer 通常也是集群的方式部署,各实例间相互不进行信息通讯。Broker 是向每一台 NameServer 注册自己的路由信息,所以每一个 NameServer 实例上面都保存一份完整的路由信息。当某个 NameServer 因某种原因下线了,Broker 仍然可以向其它 NameServer 同步其路由信息,Producer,Consumer 仍然可以动态感知 Broker 的路由的信息
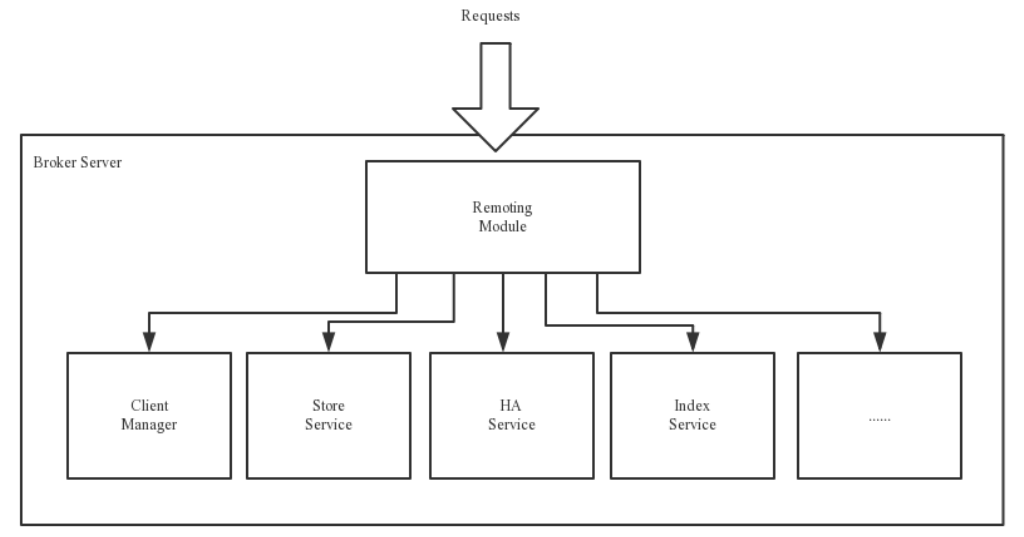
- BrokerServer: Broker 主要负责消息的存储、投递和查询以及服务高可用保证为了实现这些功能,Broker 包含了以下几个重要子模块。
- Remoting Module: 整个 Broker 的实体,负责处理来自 Clients 端的请求
- Client Manager: 负责管理客户端(Producer/Consumer)和维护 Consumer 的 Topic 订阅信息
- Store Service: 提供方便简单的 API 接口处理消息存储到物理硬盘和查询功能
- HA Service: 高可用服务,提供 Master Broker 和 Slave Broker 之间的数据同步功能
- Index Service: 根据特定的 Message key 对投递到 Broker 的消息进行索引服务,以提供消息的快速查询
# 部署架构
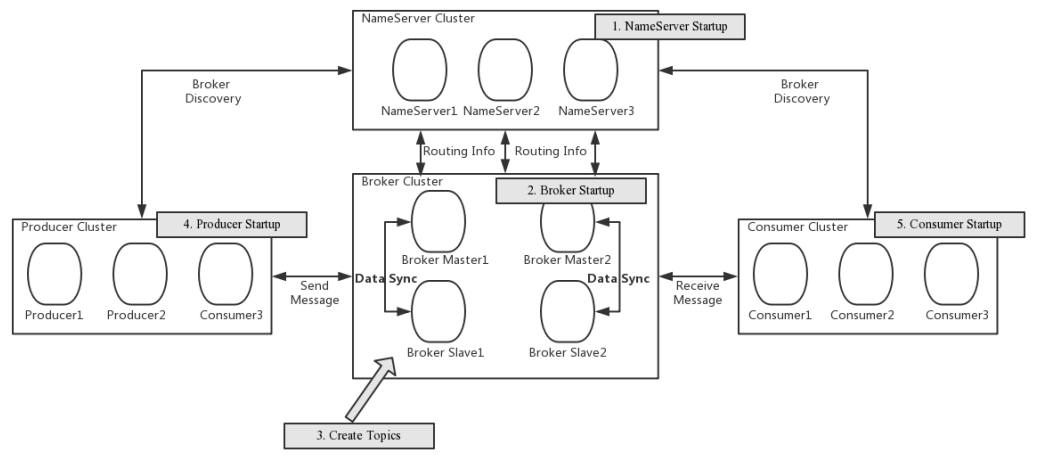
RocketMQ 网络部署特点
- NameServer 是一个几乎无状态节点,可集群部署,节点之间无任何信息同步
- Broker 部署相对复杂,Broker 分为 Master 与 Slave,一个 Master 可以对应多个 slave,但是一个 slave 只能对应一个 Master,Master 与 slave 的对应关系通过指定相同的 BrokerName,不同的 BrokerId 来定义,BrokerId 为 0 表示M aster,非 0 表示 Slave。Master 也可以部署多个。每个 Broker 与 NameServer 集群中的所有节点建立长连接,定时注册 Topic 信息到所有 NameServer。注意: 当前 RocketMQ 版本在部署架构上支持一 Master 多 slave,但只有
BrokerId=1的从服务器才会参与消息的读负载 - Producer 与 NameServer 集群中的其中一个节点 (随机选择) 建立长连接,定期从 NameServer 获取 Topic 路由信息,并向提供 Topic 服务的 Master 建立长连接且定时向 Master 发送心跳。Producer 完全无状态,可集群部署。
- Consumer 与 NameServer 集群中的其中一个节点 (随机选择) 建立长连接,定期从 NameServer 获取 Topic 路由信息,并向提供 Topic 服务的 Master、Slave 建立长连接,且定时向 Master、Slave 发送心跳。Consumer 既可以从 Master 订阅消息也可以从 Slave 订阅消息,消费者在向 Master 拉取消息时,Master 服务器会根据拉取偏移量与最大偏移量的距离 (判断是否读老消息,产生读 I/O) ,以及从服务器是否可读等因素建议下一次是从 Master 还是 Slave 拉取。
结合部署架构图,描述集群工作流程:
- 启动 NameServer,NameServer 起来后监听端口,等待 Broker、Producer、Consumer 连上来,相当于一个路由控制中心。
- Broker 启动,跟所有的 NameServer 保持长连接,定时发送心跳包。心跳包中包含当前 Broker 信息(IP + 端口等)以及存储所有 Topic 信息。注册成功后,NameServer 集群中就有 Topic 跟 Broker 的映射关系
- 收发消息前,先创建 Topic,创建 Topic 时需要指定该 Topic 要存储在哪些 Broker 上,也可以在发送消息时自动创建 Topic
- Producer 发送消息,启动时先跟 NameServer 集群中的其中一台建立长连接,并从 NameServer 中获取当前发送的 Topic 存在哪些 Broker上,轮询从队列列表中选择一个队列,然后与队列所在的 Broker 建立长连接从而向 Broker 发消息
- Consumer 跟 Producer 类似,跟其中一台 NameServer 建立长连接,获取当前订阅 Topic 存在哪些 Broker 上,然后直接跟 Broker 建立连接通道,开始消费消息