 ElasticSearch - 冲突问题处理
ElasticSearch - 冲突问题处理
# 文档冲突
当我们使用 index API 更新文档 ,可以一次性读取原始文档,做我们的修改,然后重新检索整个文档。最近的检索请求将获胜:无论最后哪一个文档被检索,都将被唯一存储在 Elasticsearch 中。如果其他人同时更改这个文档,他们的更改将丢失。
很多时候这是没有问题的。也许我们的主数据存储是一个关系型数据库,我们只是将数据复制到 Elasticsearch 中并使其可被搜索。也许两个人同时更改相同的文档的几率很小。或者对于我们的业务来说偶尔丢失更改并不是很严重的问题。
但有时丢失了一个变更就是非常严重的。试想我们使用 Elasticsearch 存储我们网上商城商品库存的数量,每次我们卖一个商品的时候,我们在 Elasticsearch 中将库存数量减少。有一天,管理层决定做一次促销。突然地,我们一秒要卖好几个商品。假设有两个 Web 程序并行运行,每一个都同时处理所有商品的销售,如图:
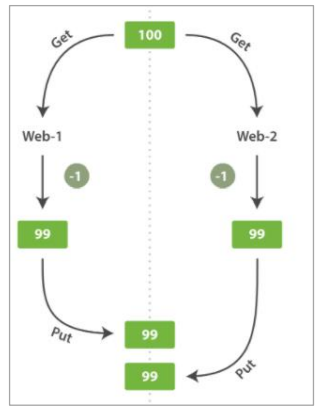
从图中可以看出 Web_1 对 stock_count(数量)所做的更改已经丢失,因为 Web_2 不知道 Web_1 的 stock_count(数量)的操作已经过期,Web_2 的操作覆盖了 Web_1 的操作。结果会认为有库存只是减少一个商品,但是卖给顾客的商品却有两个,这后果非常严重。
变更越频繁,读数据和更新数据的间隙越长,也就越可能丢失变更。
在数据库领域中,有两种方法通常被用来确保并发更新时变更不会丢失:
悲观并发控制
这种方法被关系型数据库广泛使用,它假定有变更冲突可能发生,因此阻塞访问资源以防止冲突。 一个典型的例子是读取一行数据之前先将其锁住,确保只有放置锁的线程能够对这行数据进行修改。
形象说明:悲观的认为这个世界是黑暗的,所以做任何事情前都要有拿到希望,也就是拿到锁,才进行操作。
乐观并发控制
这是 Elasticsearch 中使用的方法,它假定冲突是不可能发生的,并且不会阻塞正在尝试的操作。然而,如果源数据在读写当中被修改,更新将会失败。应用程序接下来将决定该如何解决冲突。例如,可以重试更新、使用新的数据、或者将相关情况报告给用户。
形象说明:乐观的认为这个世界是光明的,所以做任何事情都先操作完,再去拿到锁进行提交,如果锁不对,则取消操作。
# 乐观并发控制
Elasticsearch 是分布式的。当文档创建、更新或删除时,新版本的文档必须复制到集群中的其他节点。Elasticsearch 也是异步和并发的,这意味着这些复制请求被并行发送,并且到达目的地时也许顺序是乱的。Elasticsearch 需要一种方法确保文档的旧版本不会覆盖新的版本。
当我们之前使用 index(索引)的 GET 和 DELETE 请求时,可以通过返回结果看到每个文档都有一个 _version(版本号),当文档被修改时版本号递增。Elasticsearch 使用这个 _version 号来确保变更以正确顺序得到执行。如果旧版本的文档在新版本之后到达,它可以被简单的忽略掉,也就是不允许执行。
我们可以利用 version 号来确保应用中相互冲突的变更不会导致数据丢失。我们通过指定想要修改文档的 version 号来达到这个目的。如果该版本不是当前版本号,我们的请求将会失败。
假设 _version 版本号初始为 0,每次进行写操作都会加 1,当两个人同时操作时,其中一个人速度快,先操作完,导致版本号加 1,此时另一个人后操作完,发现版本已经加 1,则他的操作失败了。
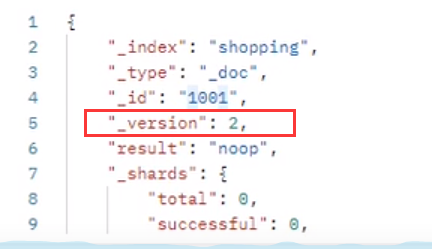
老的版本 ES 在写操作时可以指定版本,如:http://127.0.1:9200/shopping/_update/1001?version=2,如果 ES 的索引 _version 已经变成了 3,操作也会失败,所以保证 url 的 version 等于 ES 索引的 _version 版本号。当然 url 后面不指定 version,ES 索引也会自动获取 _version 号。
老的版本 es 可以直接使用 version,但是新版本不支持了,会报下面的错误,提示我们用 if_seq_no 和 if_primary_term
{
"error": {
"root_cause": [
{
"type": "action_request_validation_exception",
"reason": "Validation Failed: 1: internal versioning can not be used
for optimistic concurrency control. Please use `if_seq_no` and `if_primary_term`
instead;"
}
],
"type": "action_request_validation_exception",
{
"error": {
"root_cause": [
{
"type": "action_request_validation_exception",
"reason": "Validation Failed: 1: internal versioning can not be used
for optimistic concurrency control. Please use `if_seq_no` and `if_primary_term`
instead;"
}
],
"type": "action_request_validation_exception",
"reason": "Validation Failed: 1: internal versioning can not be used for
optimistic concurrency control. Please use `if_seq_no` and `if_primary_term`
instead;"
},
"status": 400
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
也就是说新版 url 不能直接操作 _version,如果想操作 _version,只能操作由 _version 衍生出来的 _if_seq_no 和 _if_primary_term
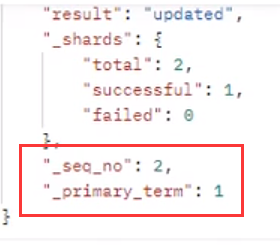
新版本改为:http://127.0.1:9200/shopping/_update/1001?if_seq_no=2&if_primary_term=2
if_seq_no 和 if_primary_term 和 _version 版本号一样,创建数据时默认为 0,进行相应的操作递增,有些操作只会导致两者中的一个递增,所以有时候发现两个的值不一样。
# 外部系统版本控制
一个常见的设置是使用其它数据库作为主要的数据存储,使用 Elasticsearch 做数据检索,这意味着主数据库的所有更改发生时都需要被复制到 Elasticsearch,如果多个进程负责这一数据同步,你可能遇到类似于之前描述的并发问题。
如果你的主数据库已经有了版本号或一个能作为版本号的字段值比如时间戳 timestamp,那么你就可以在 Elasticsearch 中通过增加 version_type=external 到查询字符串的方式重用这些相同的版本号,版本号必须是大于零的整数,且小于 9.2E+18,它是 Java 中一个 long 类型的正值。
外部版本号的处理方式和我们之前讨论的内部版本号的处理方式有些不同,Elasticsearch 不是检查当前 _version 和 url 请求中指定的版本号是否相同,而是检查当前 _version 是否「小于」url 指定的版本号。如果请求成功,外部的版本号作为文档的新 _version 进行存储。
如图当前 _version 版本是 3
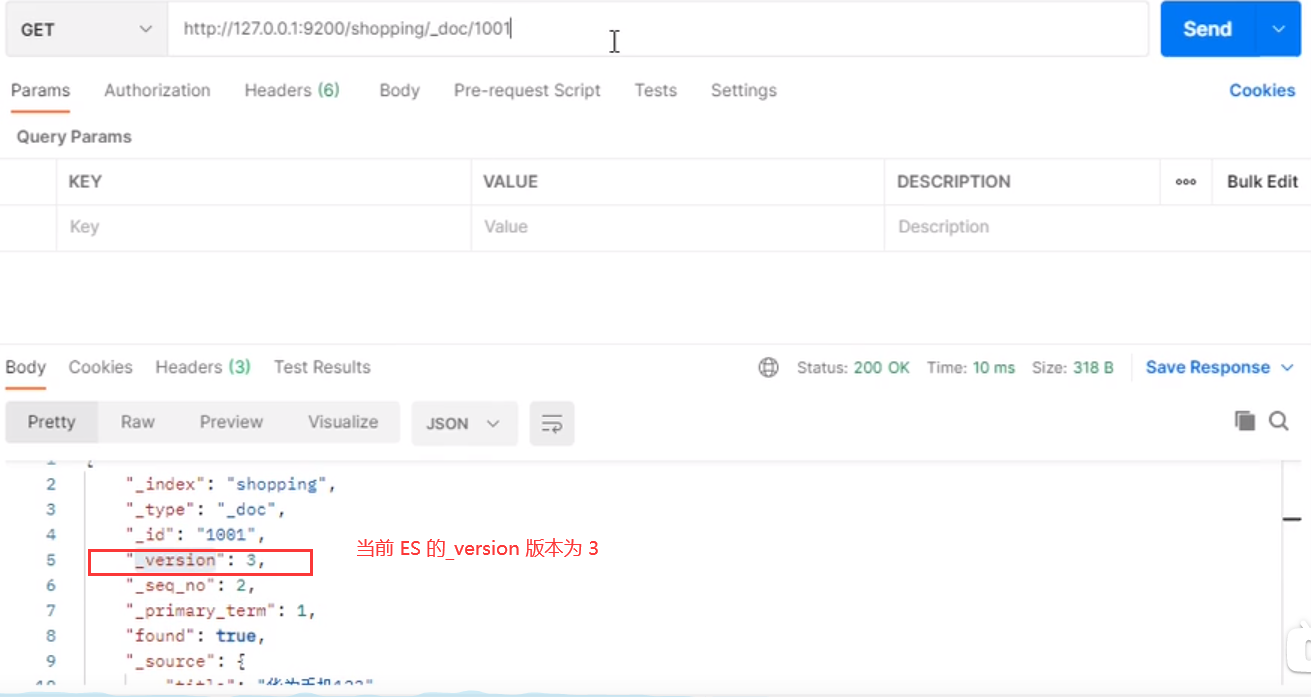
旧版不使用外部版本控制的 url:http://127.0.1:9200/shopping/_update/1001?version=3,_version 只能等于 3。
新版不使用外部版本控制的 url:http://127.0.1:9200/shopping/_update/1001?if_seq_no=2&if_primary_term=1
使用外部版本控制的 url:http://127.0.1:9200/shopping/_doc/1001?version=6&version_type=external,要求只要 url 的 version 大于 ES 的索引 _version 即可。如果等于 3,会报错。
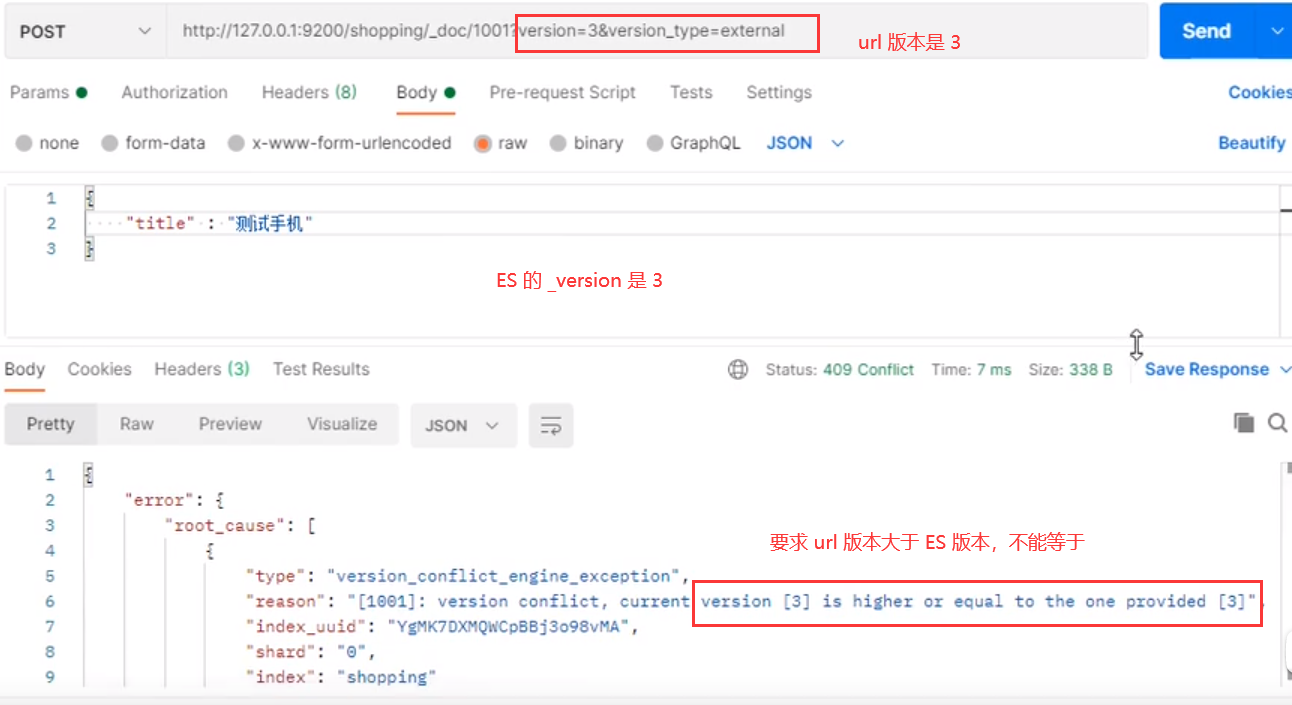
可以看出外部版本控制更加灵活,比如你不想写操作失败,完全可以在 url 里让 version = 99999,只要大于 ES 索引的 _version 即可实现写操作。
外部版本号不仅在索引和删除请求是可以指定,而且在创建新文档时也可以指定。